TDT Data Storage
Data collected or used by TDT software is stored in tanks - special directories on your hard drive. Each time you press 'Record' in Synapse, a new block is created within the tank. Within a block different stores can record different types of events at different rates. The blocks are special folders within the tank directories.
TDT Data Types
-
epocs are values stored with onset and offset timestamps that can be used to create time-based filters on your data. They can be created by the Epoch Data Storage gizmo, Logic gizmos, Stimulation gizmos, and many more.
-
If Runtime Notes were enabled in Synapse, they will appear in
data.epocs.Note. The notes themselves will be indata.epocs.Note.notes.See the Synapse Manual for more information on Runtime Notes.
-
-
streams are continuous single channel or multichannel recordings, like those stored by the Stream Data Storage gizmo, the Fiber Photometry gizmo, and many others. The structure includes the data array and sampling rate.
-
snips are short snippets of data collected on a trigger. For example, action potentials recorded around threshold crossings in the Spike Sorting gizmos, or fixed duration snippets recorded by the Strobe Store gizmo. This structure includes the waveforms, channel numbers, sort codes, trigger timestamps, and sampling rate.
-
scalars are similar to epocs but can be single or multi-channel values and only store an onset timestamp when triggered. These can be created by the Strobe Store gizmo.
The returned structure also contains an info field with block start/stop times, duration, and information about the Subject, User, and Experiment that it came from (if the block was created in Synapse).
Merging Blocks
There is a tool called TankManager that installs with Synapse that allows you to concatenate blocks directly on disk. This can create a 'super block' by combining the snippets / epocs events from multiple blocks into a single block before you export the data to another format or import to OpenSorter. It shifts the timestamps of the second block (it adds ~10 second gap in between the recordings so there is no overlap).
TankManager is a command line executable. The format for merging blocks is:
C:\TDT\Synapse\TankManager.exe --load block1 --load block2 --save outputblock
Replace the text with the two block names that you want to merge.
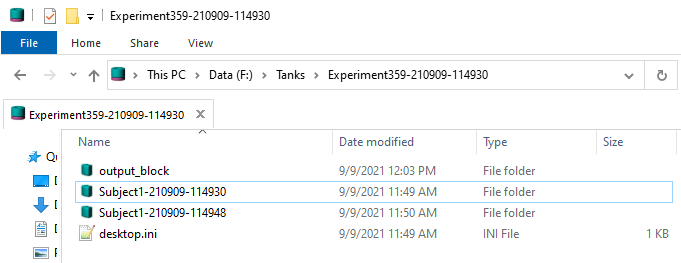
Here is an example that merges the two blocks called Subject1-210909-114930 and
Subject1-210909-114948 in the tank F:\Tanks\Experiment359-210909-114930 into a new
block called output_block inside that same tank:
-
Press the Windows key (or Windows + R) and type
cmdto enter the command line. -
Change directory into your tank folder.
-
Run the TankManager command. In this example, it is
C:\TDT\Synapse\TankManager.exe --load "Subject1-210909-114930" --load "Subject1-210909-114948" --save "output_block"

This makes a new block called output_block inside the same tank folder, which you can then
use like any other block.
Splitting Blocks
You can extract time ranges of blocks and export them to smaller blocks using the same TankManager utility described above. This works best with snippet, epoc, and scalar data types.
Here's an example that will keep the data from time t=5s to t=10s from the block C:\BLOCKPATH
and write it to a new block called C:\BLOCKPATH_5_10:
C:\TDT\Synapse\TankManager -l "C:\BLOCKPATH" -k "5-10" -s "C:\BLOCKPATH_5_10"
For example, you could use this to split up your blocks into hour long chunks like this:
C:\TDT\Synapse\TankManager -l "C:\BLOCKPATH" -k "0-3600" -s "C:\BLOCKPATH_0hr"
C:\TDT\Synapse\TankManager -l "C:\BLOCKPATH" -k "3600-7200" -s "C:\BLOCKPATH_1hr"
And so on. The data in these new blocks won't start until the first timestamp, so for later blocks there will be a large gap in the beginning. If you have an issue reading it with OpenSorter or another of our data utilities you might try following the steps in Tech Note TN0909.
Note
You might get a message during the block creation that says
Failed to set the system attribute on the block. It is okay to ignore this.