Conversion of Continuous Data into Binary Format
This guide is designed to provide TDT data users various options for converting their data into binary format, CSV, EDF, DDT, and other formats for import into third-party applications such as Spike2, Kilosort, Plexon Offline Sorter, or others. Please look through the options to see which one is best suited for your needs.
Scaling Notes
Different applications may have different scaling requirements. Please always check your scaling across multiple applications to ensure you are scaling your data properly.
Please compare the TDT block or SEV data in MATLAB or Python or OpenScope (https://www.tdt.com/docs/lightning/openscope/ and https://www.tdt.com/docs/openscope/) vs your end-use application (POS, Spike2, or anything else) to make sure the scaling is correct.
TDT streaming data is almost always stored as 32-bit floating point values in units of Volts.
Check the StoresListing.txt file inside the block folder for a full listing of the streaming data stores.
The information includes: Gizmo name, store name, data format, scale factor, and sampling rate.
Here is an example:
Object ID : Wave1 - Stream Data Storage
Store ID : Wav1
Format : Float-32
Scale : Unity
Rate : 24414.1 Hz
Note
Note that the sampling rate shown in this file is rounded. The exporting tool will export the exact sampling rate. For TDTexport, this is a text file that is created next to the binary files.
When exporting as int16, generally you will use a scale factor of 1e6. This converts the
units to microVolt.
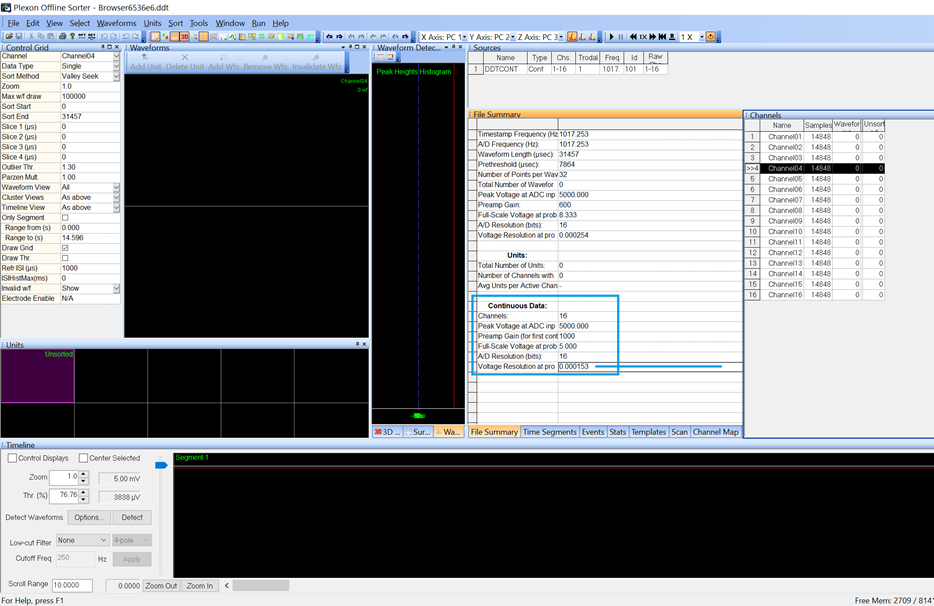
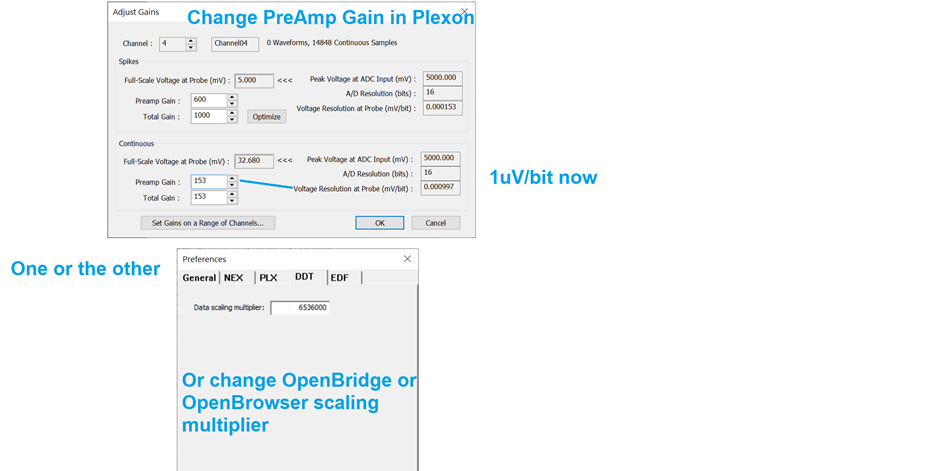
One common example of necessary scaling is when exporting to Plexon Offline Sorter. You may need to adjust the scale in Plexon under the Preamp/Total gain to have a gain of 153, as shown in the image in the Using OpenBrowser or OpenBridge section. This is because Plexon imports DDT files as 16-bit files with an assumed max resolution of 5 V, which makes the resolution 0.153 uV/bit, but you will probably want to adjust that resolution to be 1 uV / bit. However, import your data without this change first to see if the scaling is off, then adjust accordingly and check again.
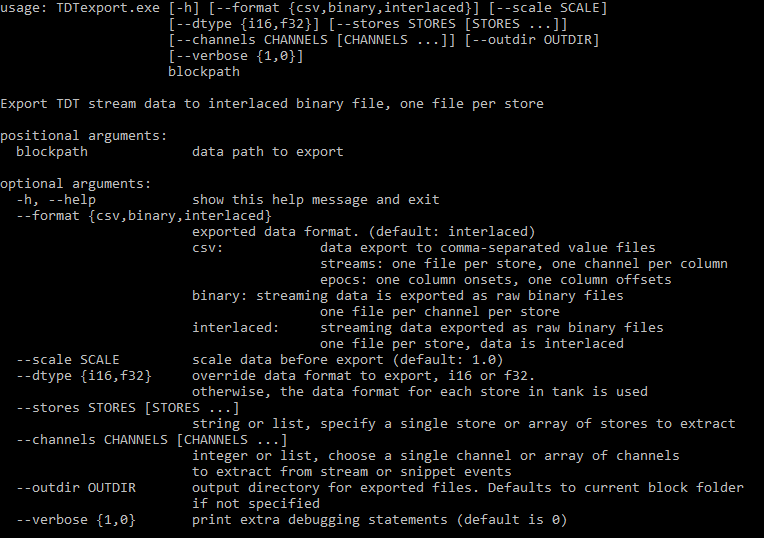
Using TDTexport
TDTexport is a command-line tool for exporting continuous data to binary or CSV files. Here is a link
to the file you will need: https://www.tdt.com/files/tech/TDTexport.exe (download will begin automatically).
Copy this file into C:\TDT\ and use it from the Windows Command line like this:
> C:\TDT\TDTexport.exe C:\TDT\OpenEx\Tanks\DEMOTANK2\Block-2 --scale 1e6 --dtype i16 --channels 1 3 5 --stores Wav1 Wav2
In this example, channels 1, 3, 5 of the Wav1 and Wav2 stores from block C:\TDT\OpenEx\Tanks\DEMOTANK2\Block-2
are scaled by 1e6 and converted to interlaced i16 files. The files will be named
C:\TDT\OpenEx\Tanks\DEMOTANK2\Block-2\Wav1.i16 and C:\TDT\OpenEx\Tanks\DEMOTANK2\Block-2\Wav2.i16.
This method will export the data as an interlaced binary file (although you can specify interlaced or
individual channels), which applications like Kilosort, Spike2, and Plexon Offline Sorter can directly read.
You may need to change the file extension from .i16 to .bin for Kilosort.
It also exports a summary text file that includes the options used for the export and the exact sampling rate of the data stores. Here is an example.
Path: G:\TEMP\Block-81\
ScaleFactor: 1.0
Stores:
Name: SU_4
Freq: 24414.0625
NChan: 16
Here is the full list of options:
Using OpenBrowser or OpenBridge (EDF, DDT, PLX)
Use OpenBrowser for conversion of files into EDF format for import into EDF readers such as Polyman, Sleepsign, and others. You can export single or multiple channels into a single EDF output file.
You can follow along with this Lightning Video and read the Open Browser User Guide.
Note
Avoid pressing 'Refresh' in OpenBrowser like the video shows if your data is very long. This could slow down or crash OpenBrowser.
Both OpenBrowser and OpenBridge can convert continuous data into DDT file format, which can be read by Plexon Offline Sorter using the Import and Continuous Binary option (newer versions of POS do not read DDT files directly. It might be simpler to use TDTexport instead, so try both methods if you are unsure.
Here is a link to the OpenBrowser manual exporting section and here is the OpenBridge manual.
DDT files have a data offset of 412 samples, so be sure to use the correct offset when importing.
See the Scaling Notes section for important scaling information.
Using the Python SDK
You can use the python SDK to import block data, SEV files, or subsets of streams or channels using the
read_block function, which is a part of the tdt module. The read_block function also has an export option
that you can call. TDTexport is essentially a command line wrapper around this function.
For example:
from tdt import read_block
>>> data = read_block('D:\\Tanks\\Scale-210527-121349\\Subject1-210527-121350', export='interlaced', outdir='D:\\Tanks\\Scale-210527-121349\\Subject1-210527-121350', prefix='test')
read from t=0s to t=16.71s
exporting TEV stream Wav1...
...100%, 0 seconds elapsed
exporting TEV stream Wav2...
...100%, 0 seconds elapsed
This is going to export all the data in streams, so if you want to only export a certain
subset be sure to only import that subset to begin with.
Use print(read_block.__doc__) to see the other options that allow you to select specific stores, time filters,
etc, and other export options, like 'binary' and 'csv'.
Using the MATLAB SDK
This binary export script example can be used to export as i16 of f32. Be sure to pick the appropriate scaling for whichever format you select.
For Kilosort, use a scaling factor of 1e6 and export to i16. Then, change the file names from .i16 to
.bin and they should work in Kilosort. If you have SEV files, TDTbin2mat will call SEV2mat, so it should
work on just the relevant streams if you give it the right Stream Store name. If you use SEV2mat directly,
then you may need to move the structure that gets imported into a data.streams.(StoreName) structure first.